在微博和Keep网站上图片抓取实现方法
背景:由于一些网站中,是用js进行加密(Ajax加载),用request或是beautifulsoup对html进行解析无法提取出图片的链接。一般情况下,爬虫可以通过发送Ajax请求以加载页面,抓取url。但是最近微博登陆需要进行验证,只用cookie无法访问相关页面。而九宫格的手势验证或是验证码处理的例程也过于复杂。因此本文实现一种简单的自动Ajax加载的方式。
准备环境:
1.AutoHotKey脚本程序
2.chrome浏览器 + Tampermonkey插件
3.python3
1 实现路线
1.用AHK脚本模拟PageDown的按键,让页面自动向下滚,加载出所有的图片
2.用js脚本在浏览器console中输出所有图片链接,手动保存到本地.log文件
3.用py对url进行筛选处理
4.配合Aria2或者IDM下载
2 源代码
2.1 AHK代码
安装ahk程序后(官网:https://www.autohotkey.com/),新建.ahk文件或是用.txt改后缀,将以下代码复制进去。
1 |
|
2.2 js代码
这是修改greasfork网站上tankywoo所写的代码,网址见参考文献[1]。
在tampermonkey中新建脚本页面,复制一下代码保存。
修改后代码如下:
1 | // ==UserScript== |
2.3 py代码
1 | # -*- coding: utf-8 -*- |
3 示例演示
1.双击启动ahk脚本
2.在chrome应用商店中安装Tampermonkey,或crx导入。打开Tampermonkey管理面板,新建脚本,复制代码,并保存启动。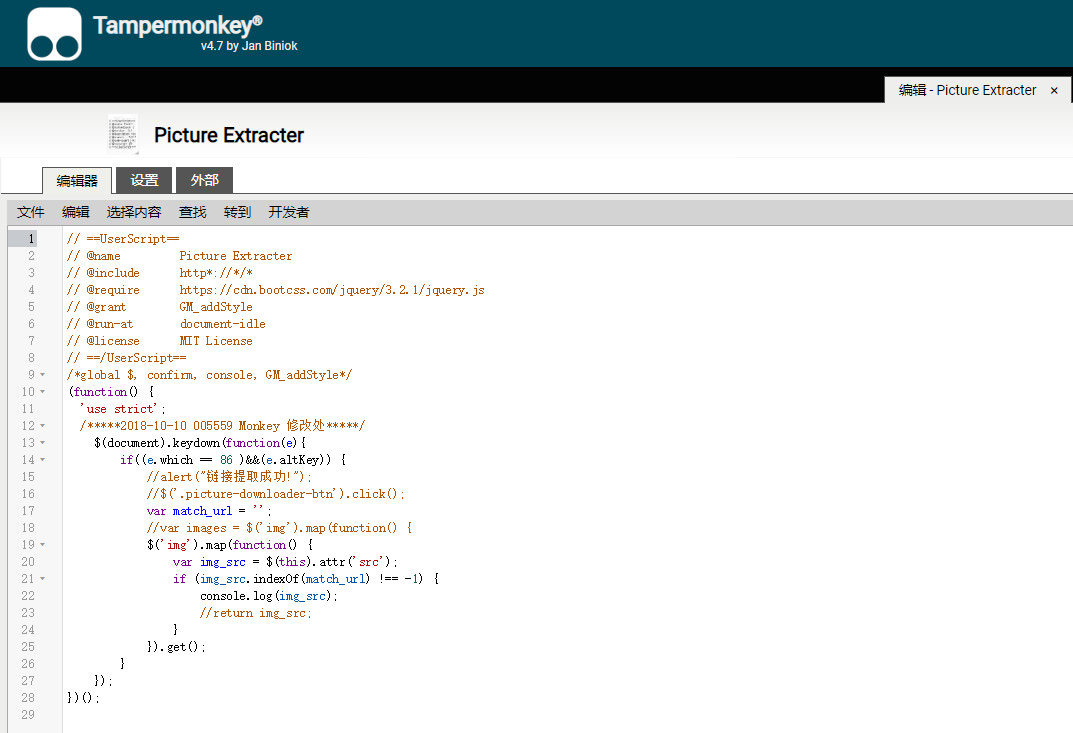
3.浏览器打开 Keep_活动 个人页面 https://www.gotokeep.com/users/56d3fe83ca2f02ff1310b1e6
4.按下F7页面自动向下滚动,按下Esc停止滚动。
5.按下F12,点击console,打开控制台。右键清空 “Clear console”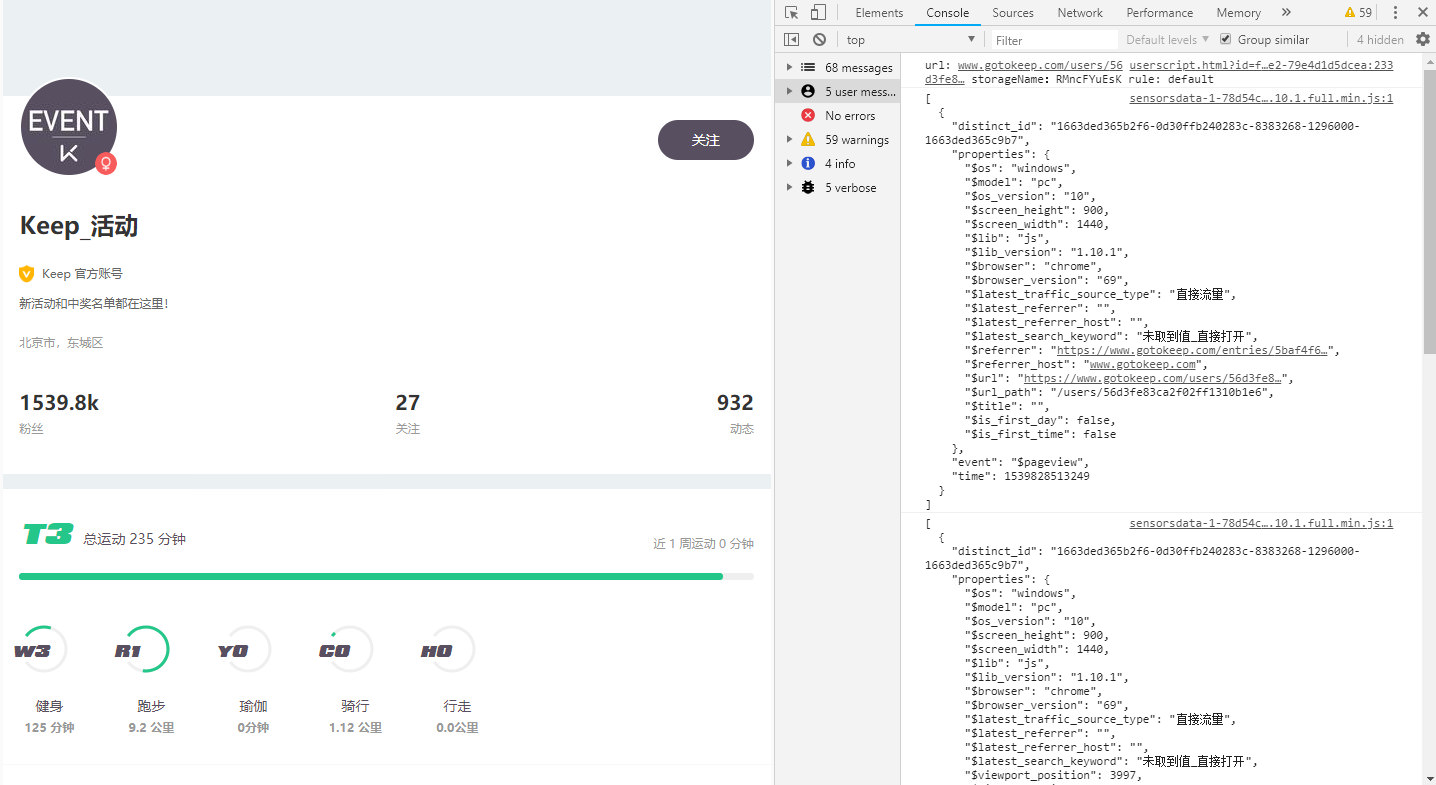
6.点击左侧网页,按下Alt和v组合键,可以看到第一列的图片url全部解析完毕。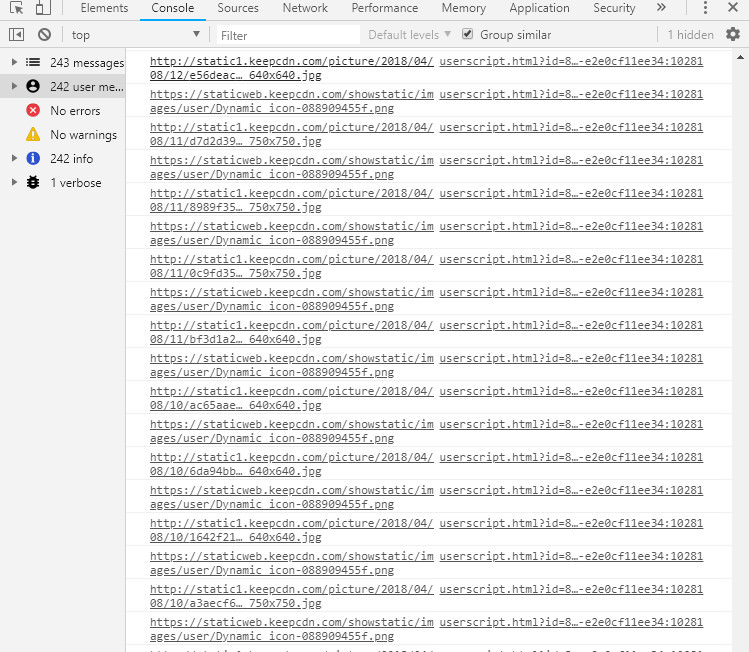
7.右键console,点击save as 保存为 todo.log,与.py放置同一文件夹。
8.运行.py,发现多了一个Done.txt,图片url整理完毕。
注意:
有的时候提取的图片并非原图,所以需要对url进行关键词替换。以微博评论图片为例:
小图链接为:http://wx1.sinaimg.cn/wap360/0072UHXNly1fwa5c0d6i1j30hs0hs40k.jpg
而原图链接:http://wx1.sinaimg.cn/large/0072UHXNly1fwa5c0d6i1j30hs0hs40k.jpg
需要将wap360 替换成 large。
9.复制url,配合Aria2(推荐AriaNg)或IDM食用。
参考文献:
 wechat
wechat alipay
alipay







