背景:作为一个RSS的爱好者,一直在尝试用各种方法烧制feed。最早是feed43,还尝试过huginn,到近期很火的RSSHub,尽管他们的评价都非常的高,但是都用各自的缺点。本文先粗略比较以上三种方式的优缺点,再说明用python制作rss阅读源的详细过程。
1.feed43(已被墙)
feed43学习成本最低,无需自己搭建平台,但是免费版本是6小时更新一次源而且只能抓取文章的标题和时间,无法显示内容,虽然可以通过https://fivefilters.org 二次显示内容,但同样有诸多限制,很难满足需求。
2.huginn
在各个网站上被称为RSS烧录神器,而且在github上21k的星标https://github.com/huginn/huginn ,但是实测其爬虫的功能很一般。你需要将他部署在vps上,(我部署过三次,成功过两次,两次都是用docker),部署成功后进入web控制台界面,添加agent,就可以运作了。界面和操作feed43差不多,但是功能更为强大,可以自定义抓取和更新时间,还可以嵌套使用获取全文。但是其获取内容是依靠的xpath和css获取,谷歌浏览器有一款xpath helper 的插件很好用,但是仍会出现获取内容为空的情况,而最大的问题是,没有办法进行调试,不知道问题出现在哪里,真的非常痛苦。经过两次尝试之后,我最终放弃了。
RSSHub现在的源非常的多,更新速度和内容完整都非常的好,共享的机制也很好。现在我基本上先在RSSHub上先找源,而且有对应的浏览器插件排查非常快速。但是他的学习成本也很高,需要nodejs的基础,可以自己部署也可以写好脚本给官方添加路由。那么对于一些特殊的源,去部署RSSHub,再用nodejs编写爬虫脚本,对于我来说稍显吃力,于是这个方法我也搁置了。
总结:
工具
内容完整度
抓取间隔
部署
学习成本
feed43
标题
免费版6小时
无
低
huginn
完整内容
自定义
vps+docker
高
RSSHub
完整内容
自定义
vps+docker
很高
根据以上的分析,我决定寻一个可以自己定制一个可以不限时间,不限内容,简单部署的方法(当然,整体的时效还要依赖客户端抓取源的速度,这里指源的更新速度)。后来我发现RSS源本质是XML或者json的数据,由RSS软件去订阅这些源再定时抓取源的文章,将新的新的文章推送给订阅用户。那么只要我自己脚本写XML或者json就算是完成制作源的工作了。于是我用python来完成这个功能。因为python爬虫抓取网页的能力非常强,而且python也支持对XML文档的解析和编写。
整体的流程图如下:
准备环境:
1.python3
1 编写python爬虫脚本 这里我以电脑爱好者官网为例:*http://www.cfan.com.cn/technic/ *
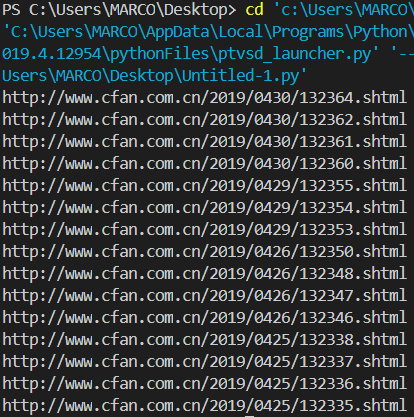
1.1 抓取首页所有文章的url 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import requestsimport bs4import timeimport osimport sysimport codecssys.stdout = codecs.getwriter("utf-8" )(sys.stdout.detach()) url_index = 'http://www.cfan.com.cn/technic/' def get_urllist (url ): urllist = [] soup = bs4.BeautifulSoup(text_index, 'html.parser' ) for pos in soup.find_all('div' ): if pos.get('class' ) == ['left-post' ]: print (pos.contents[3 ].get('href' )) urllist.append(pos.contents[3 ].get('href' )) def get_text (url ): try : r = requests.get(url, timeout=10 ) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except : print ('获取文本失败' ) if __name__ == '__main__' : text_index = get_text(url_index) get_urllist(text_index)
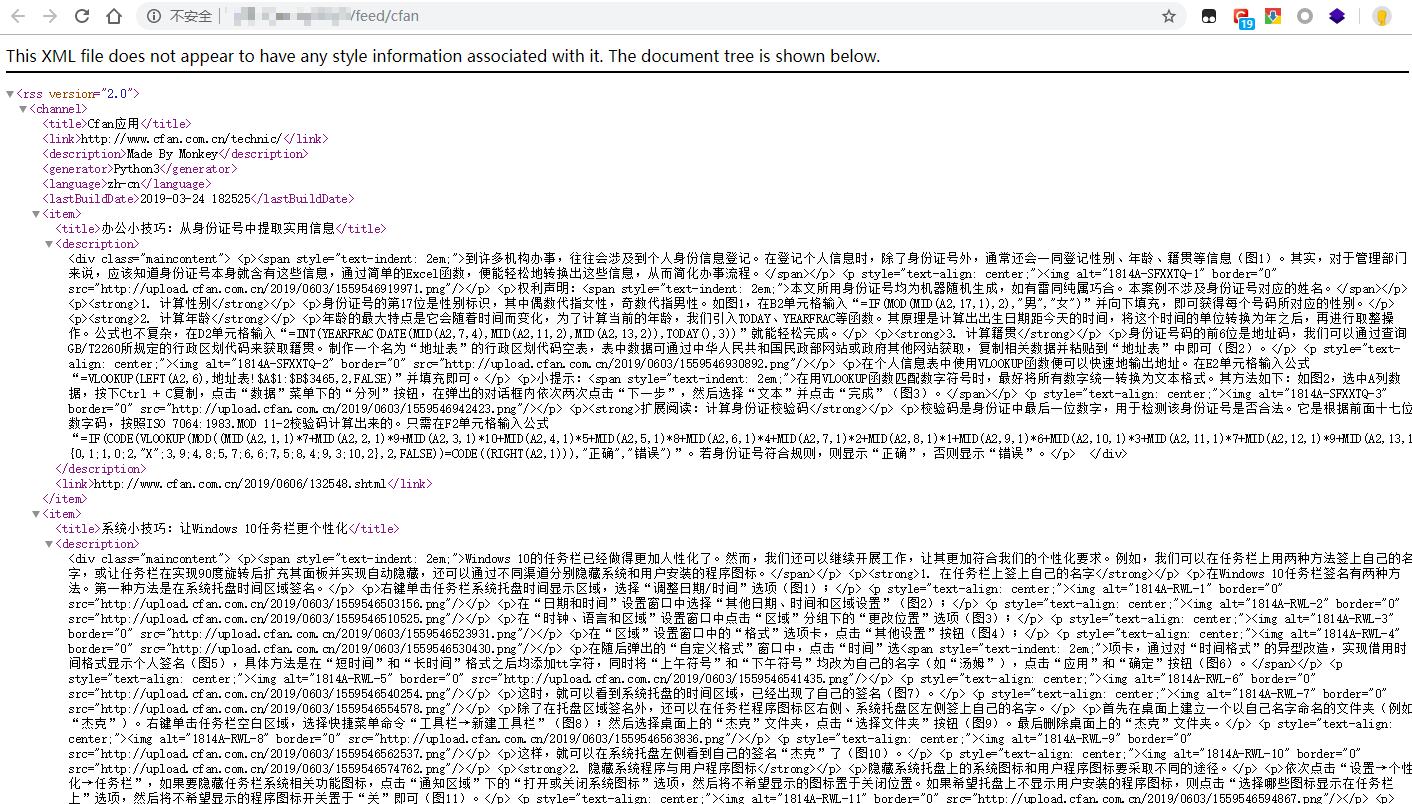
输出结果如下:
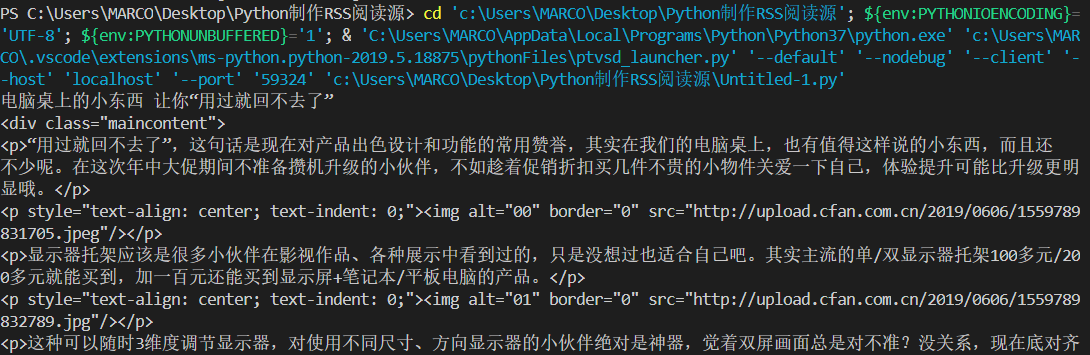
1.2 抓取各个文章的内容 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def com_html (url ): html_text = get_text(url) soup = bs4.BeautifulSoup(html_text, 'html.parser' ) for link in soup.find_all('h1' ): title = link.text break for link in soup.find_all('div' ): if link.get('class' ) == ['maincontent' ]: content = link break print (title) print (content)
输出效果如下:
2 记录数据 2.1 记录抓取过的文章 每次抓取文章前都会判断url是否存在于txt中,如果存在说明已经抓取过了,不需要重复抓取。如果不存在,就需要继续操作,然后将url记录在txt中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 def record (slst ): key = slst flag = 1 try : with open (path_database, 'r' , encoding = 'UTF-8' ) as f: line = f.readlines() f.close() except FileNotFoundError: with open (path_database, 'wb+' ) as f: line = '' f.close() for i in range (len (line)): if key == line[i].strip('\n' ): print ('Repeated! ' + key + ' ' + str (i)) flag = 0 if flag == 1 : com_html(key) url_log.append(key) with open (path_database, 'a' ) as f: f.write(key + '\n' ) f.close
2.2 记录工作日志 记录抓取的时间,更新数目。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def log (): time1 = time.strftime("%Y-%m-%d %H:%M:%S" , time.localtime()) try : with open (path_log, 'r' , encoding = 'UTF-8' ) as f: old_log = f.read() f.close() except FileNotFoundError: with open (path_log, 'wb+' ) as f: old_log = '' f.close() with open (path_log, 'w' , encoding = 'UTF-8' ) as f: f.seek(0 ,0 ) f.writelines('----更新时间:%s-----\n' %time1) for i in range (len (url_log)): f.seek(0 ,2 ) f.writelines(url_log[i] + '\n' ) f.seek(0 ,2 ) f.writelines('%s 条更新完成。\n\n' %len (url_log)) f.seek(0 ,2 ) f.write(old_log) f.close()
3 编写xml 3.1 空白的文档 其实rss源是由空白文件和各个文章的内容节点组成。空白文件,包括xml头,rss头,rss源的标题,链接以及其他信息。将以下代码保存为 XML_Cfan.xml,与python脚本在同一个文件夹下。
1 2 3 4 5 6 7 8 9 10 11 <?xml version='1.0' encoding='utf-8'?> <rss version ="2.0" > <channel > <title > Cfan应用</title > <link > http://www.cfan.com.cn/technic/</link > <description > Made By Monkey</description > <generator > Python3</generator > <language > zh-cn</language > <lastBuildDate > 2019-03-24 182525</lastBuildDate > </channel > </rss >
3.2 插入内容节点 在1.2中,获得的各个文章的内容,要逐个做成节点插到XML的结构树中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from xml.etree.ElementTree import ElementTree,Elementimport osdef add_newxml (title,content_html,link ): dir_path = os.path.dirname(os.path.realpath(__file__)) file_name = dir_path + '/XML_Cfan.xml' tree = ElementTree() tree.parse(file_name) root = tree.getroot() item = Element('item' ) root[0 ].insert(6 ,item) item_title = Element('title' ) item_title.text = title item.append(item_title) item_description = Element('description' ) item_description.text = content_html item.append(item_description) item_link = Element('link' ) item_link.text = link item.append(item_link) tree.write(file_name,encoding='utf-8' ,xml_declaration=True ) if __name__ == '__main__' : title = '' link = '' content_html = '' add_newxml(title,content_html,link)
那么,最核心的部分已经完成了。可以在本地测试一下,整个脚本文件应该看起来是这样:
4 允许公网访问xml 制作好的xml虽然可以自己阅览,但是如果要让RSS客户端能够抓取,还需要xml能够被其他设备访问,能够相应http请求。要完成这一步需要两个步骤:1.一个公网ip。2.把xml变成静态的网页。
这里提供一个思路:VPS + nodejs(express)
购买云服务器之后会自动分配一个ipv4地址,有了公网ip,接下来就需要再ip下添加一个路由映射到XML,目标效果就是在浏览器上输入特定的网址可以打开加载出我们的XML。这里需要用到加载静态网页的方法。方法非常之多,而我采用的nodejs+express的框架。nodejs代码如下:
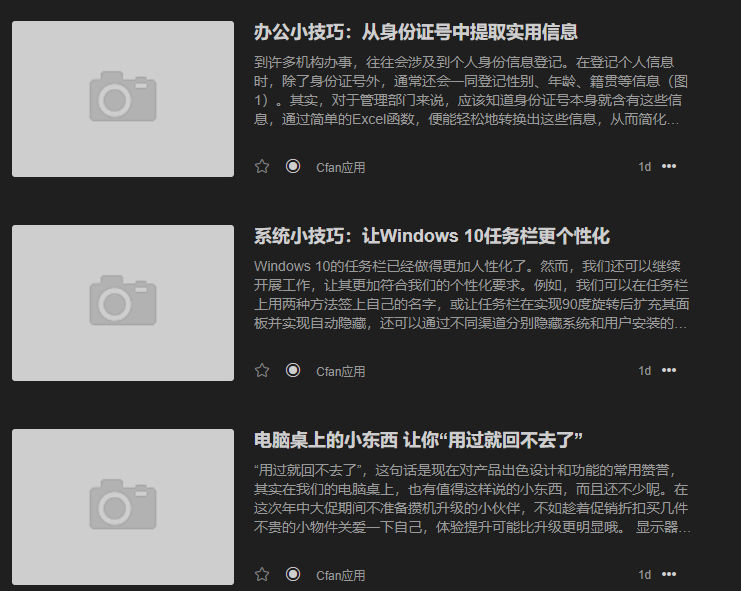
1 2 3 4 5 6 7 8 9 10 11 12 13 var express = require ('express' );var app = express();var http = require ('http' ).Server(app);var PORT = 8080 ;app.use(express.static(__dirname)); app.get('/feed/cfan' , function (req, res ) res.sendFile(__dirname + 'XML_Cfan.xml' ); }); http.listen(PORT, () => console .log('Express RssXml is listening on port ' + PORT));
访问页面如下:
到这里我们完成了90%的工作,所有的核心思想都在上面。但是仍没有实现完全的自动化,因为python的脚本,只有每次执行之后,才会被触发去抓取新内容。另外,一旦我们运行脚本的平台(比如个人电脑)一旦关机或者断网,所有的脚本全都失效无法正常工作。后面的情况我们用云服务器解决,可靠的云服务商会保证服务器可以永远工作,这也是VPS的另一个好处。下面我就继续最后10%的工作如何完成。
5 自动触发脚本 一般来说,购买的云服务器都是Linux的系统,在没有桌面端的情况下,个人用户用指令去执行任务会遇到许多困难,但是作为服务器来说,Linux更加稳定和高效。把写好的程序上传到linux云服务器上,利用crontab设置自动触发py的命令,操作如下:
sudo vim /etc/crontab
在末尾添加一行,表示每30分钟,以root用户,执行python3 /home/Spyder_Cfan.py
*/30 * * * * root python3 /home/Spyder_Cfan.py
6 添加源到客户端 将url添加到RSS客户端(我用的是inoreader ),显示结果,大功告成。
7 完整代码下载
https://github.com/Monkey1GIt/python2xml



 wechat
wechat alipay
alipay






